Lecture 7
Intro to Databases and Firebase
A lot of the apps we have been making work and maintain states throughout the lifetime of the app, but lack one critical feature - if we restart the app or refresh the page, all of our data disappears! We need some kind of persistent storage for this data, which is where databases get involved.
Why do we need a database for our backend?
- Data stored within Node.js is per instance
- Most applications require persistence
- Data analysis
- Performant data location
- Offloading unneeded data from memory
Types of Databases
| SQL | NoSQL |
|---|---|
| Stores data in tables, utilizing rows and tables | Stores data in documents |
| Has predefined schema, which can be relational (tables can provide access to related data points in other tables) | Can abide to any structure you want (no schema or partial schema) |
| Less expensive for smaller datasets and can execute complex queries | Better for large sets of data, but not complex queries |
| Less flexible | More flexible (can be used with most popular languages) |
| Leans towards strong consistency | Favors eventual consistency (here may be some delay in getting response back) |
| Vertically scalable (need more computing power on one machine to store more data) | Horizontally scalable (can distribute storage and compute power on multiple machines |
| Examples: MySQL, PostgreSQL | Examples: Firebase, MongoDB |
What is Firebase?
- Firebase is a Backend as a Service (BaaS) offered by Google
- Allows you to store data
- Host websites
- Authentication
- NoSQL DB
- Not only SQL
- Non relational
Why Firebase?
- Real-time operations
- Firebase Authentication
- Built-in analytics
- Also supports hosting/deployment
- Integration with other Google services
- Structure we’re familiar with!
Getting Started With Firestore
Let's finally start talking about how we can perform operations on our database using Typescript.
Firestore Data Model
Firstly, a Firestore database is NOSQL, document-model database generally comprised of multiple collections,
which may house differing data. To take a simplified example, a Cornell database
could have some of the following collections: people, courses, locations.
Certain collections may be broken up into multiple collections, such as breaking
up people into staff and students or even into subcollections, which we will
not discuss but they exist for those who are interested, as we could simply distinguish
different people with a field, such as role: Student | Staff. The id of a collection,
which is what is used to access it, is generally a descriptive name of the collection.
A typical model, including that of Firestore, has collections comprised of documents,
or docs for short, which would be the "items" we want to store. Going back to our
Cornell example, our people collection would probably have documents pertaining
to students or staff at Cornell, with each document being uniquely identified
by a unique id, like netid. Within each document, we may have fields like age
and address, so in this way, documents can be thought of as Objects. But as you
may have already noticed, some documents would have fields that others don't - students
may have a major field while staff may have a salary field. As it turns out, that's
totally ok! Generally speaking, having more uniform document fields across a collection
gives stronger guarantees about each document and is often a more natural fit, but Firestore
does not require us to have uniform fields within all the documents of a collection, which gives
us a layer of flexibility.
Using the following code, we can create references to both the people collection and
specific docs such as the myl39 doc (which represents me!).
const peopleCollectionRef = db.collection('people');
const michelleDocRef = peopleCollectionRef.doc('myl39');
Firestore Operations
We generally refer to database operations as CRUD, which stands for:
- Create/Insert - Create a document (will fail if the document exists)
- Read/Find/Query - To search for documents based on their properties
- Update - Update an existing document (will fail otherwise)
- Delete - Delete an existing document
Create
To create a document in Firestore, we primarily use the set function.
Here's an example of setting a document in our people database.
await peopleCollectionRef.set(michelleDocRef, {
year: '2023',
age: 20,
});
set will write to the document myl39 within the people collection, creating it
if it does not yet exist.
Note that ids are autogenerated if the name of the document is not specified in the doc() call with the set function.
Read
To read data in Firestore, we first need to take a snapshot of the data we want to read. Then, we check if that snapshot of the document we want actually exists before trying to extract its data.
Here's a simple example logging my data. Notice I log doc.data() and not doc because
the former is where the data actually resides.
const doc = await peopleCollectionRef.doc(netid).get();
if (doc.exists) {
console.log('Document data:', doc.data());
} else {
console.log('No such document!');
}
We can also perform querying on collections, where we filter the database with certain
criteria. Here's a simple example of looking for all people in people who are 20.
const snapshot = await peopleCollectionRef
.where(“age”, “==”, 20)
.get();
snapshot .forEach((doc) => {
console.log(doc.id, ' => ', doc.data());
});
Line by line, we first take a snapshot of all such documents in the query specified, and then, we perform the same doc.data() approach. We do not need to check if each doc exists because we are using a for loop, and if a doc does not exist, it simply would not be part of the for loop.
We can also order our search results. Here is an example of querying for people who are at least 20 and then ordering them in descending order.
const snapshot = await peopleCollectionRef
.where(“age”, “>=”, 20)
.orderBy(“age”, “desc”)
.limit(3).get();
querySnapshot.forEach((doc) => {
console.log(doc.id, ' => ', doc.data());
});
Update
Updating a document will only replace the specified fields within a doc and maintain
unmodified fields. So the following code keep the last field but change age and
first.
await peopleCollectionRef
.doc(‘myl39’)
.update({ age: '20', first: 'michelle' });
Note if the document we're trying to access is not available, an error will occur.
Delete
Deleting a document removes it from the collection.
await peopleCollectionRef
.doc(‘myl39’)
.delete();
Callback/Promise-based vs Real-Time Queries
| Promise-Based | Real-Time |
|---|---|
| If you need the data now, you can query for it | You already have the data |
| Data queries can be decentralized (done in any component) | Data queries are fetched and memoized through centralized (React) hooks |
| Querying data is imperative, but can quickly become hard to maintain and track (and you lose some of the advantages of a declarative web UI framework) | Up-front cost to query data pays off (because you don't hopefully have to query it again) |
| There is no cleanup code | You first have to "subscribe" to changes in the data, then unsubscribe after you are done (kind of like opening and closing a file stream when reading a file) |
What do Callback/Promise-based vs. Real-Time Queries Look Like?
Promise-based queries are single queries that return a single async result. So, they are run once and then passed along downstream to children and other descendants of your component. Typically, they are used to react to some update (i.e user clicks a button, a component loads).
Real-time queries are single queries that return a stream of async results such as weather data. These types of queries are used once the data is listenable and needs to be "subscribed to". These take a stream of results and are built on top of wbe sockets, which are abstractions over a byte stream. So, they're good for ... real-time applications.
How Do Callback/Promised Based vs. Real-Time Queries Work?
Promise based queries typically calls some backend API route, which fetches and returns data to you. They're built on top of traditional HTTP requests.
Real-time queries might call a backend route to pass data over to a web socket or it'll simply use an API library to makes calls directly to a database (ex. Firebase Firestore call). These queries are usually wrapped in a library like RxJS's observable data type or function calls that allow you to subsribe to changes.
Choosing a Querying Method
As described in the first section, the type of queries your application will use will affect the app's architecture. In particular, real-time queries play nicely with having a centralized query that runs over a listenable data access object that is "owned" either by
- a top-level component (OK in small apps, but prone to prop drilling in more complex apps), or
- a custom React hook that wraps an effect (triggering an update when the data access object publishes a new version of the data)
That is not to say that your app cannot use both types of queries. It is just that a real-time application requires a specific architecture in which all data is queried first and passed along to components as props or referenced by components via (potentially custom) React/Redux hooks. This does not play nicely with callback/Promise-based queries because the data from the callback/Promise-based queries may be in an inconsistent state by the time the data from a real-time query has updated.
Firebase Firestore Application: Callback/Promise-based or Real-Time Queries
Firestore offers you a database that nicely organizes your data into documents and collections (groups of documents). It allows you to build queries that can either
- return once with a single snapshot of data (a Promise-based query), or
- allow you to hook into the data's live values (a real-time query).
Firestore Real-time Queries
Provides collection + document data as an listenable (subscribable) data object
- As soon as a collection updates, the collection access object publishes a new version of the collection
- As soon as a doc updates, the doc access object publishes a new version of the doc This can be passed as a React prop or an effect dependency, which triggers a component update!
Anatomy of a Firebase Firestore Real-Time Application (The "Full" Stack)
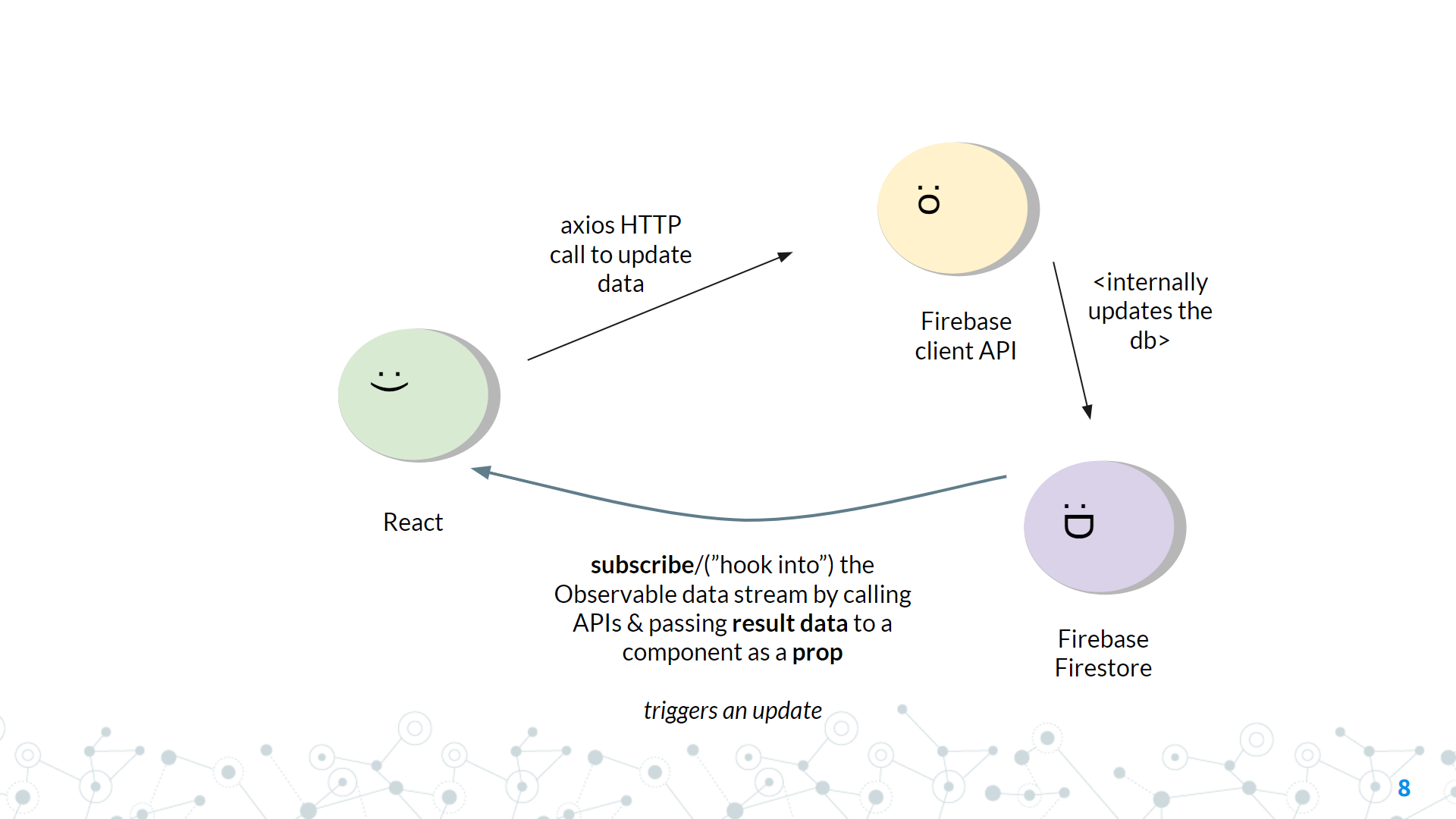
Unlike callback/promise-based queries, the connection between updating and fetching data is completely gone. Updating data occurs along an entirely separate channel from subscribing to the data. This means that implementing calls to update data will look very different
Miscellaneous Advice
When designing a system:
- avoid two-way dependencies (or as many dependencies as possible)
- as with React & declarative web frameworks, one-way data binding is the way to go
- avoids: more things to update
- avoids: more surface area for synchronization errors
This philosophy helps us prefer real-time queries over Promise-based queries, because there is only a single dependency for the queried data, rather than the set of all the decentralized Promise-based queries.
Sample code
This week's sample code starter can be found in the files under this directory.
Instruction to connect Firebase with demo code
Create new Firebase webapp and database
- Login to Firebase Console and Add project:
- Add desired name for the project (ex:
trends-demo) - Turn off Google Analytics for simplicity (can manually integrate later)
- Create new Webapp:
- On landing page, click web icon (
</>) OR click Add app to create new webapp - Choose app nickname (ex:
lec7-demo) then register - Use default choice in Add Firebase SDK then continue to console
- Create new Database:
- On left sidebar, under Product categories, expand Build, then choose Firestore Database
- Click Create database, choose location in United States
- Start in test mode (allow anyone to read and write, need to be changed when deployed)
- Add some data to database for testing (collection -> document -> data fields)
Connect your codebase to Firebase
This guideline specifically refers to this lecture's demo code
- On left sidebar, click Setting icon (next to Project Overview), then Project settings
- Choose Service accounts tab, then Generate new private key (do not expose this key on internet - ex: Git, each of the team members need to generate separate private key themselves)
- Move the newly downloaded json file to your project backend folder (
server), then rename it toservice_account.json - Add
service_account.jsonto your.gitignore(in your root folder) - Modify your
server/firebase.tsto get database as bellow:
import { initializeApp, applicationDefault, cert } from 'firebase-admin/app';
import { getFirestore } from 'firebase-admin/firestore';
import serviceAccount from './service_account.json';
const app = initializeApp({
credential: cert(serviceAccount),
});
const db = getFirestore();
export { db };
- Import
dbwherever you need to interact with the database!
import { db } from './firebase';